14 minutes
攻防世界进阶区日常训练001
攻防世界 RE 进阶区 日常练习 001
ISCC比赛临近,CTF比赛题目也要开始继续训练起来 前段时间,由于准备升学相关的事宜,没有进行比赛的训练 手感相对而言,有些生疏 简单从攻防世界平台找几道逆向的题目进行简单的练习下
这几道题目主要都是使用IDA pro的远程调试功能,使用虚拟机搭配IDA进行远程调试
re2-cpp-is-awesome
先查看一些文件的简单信息
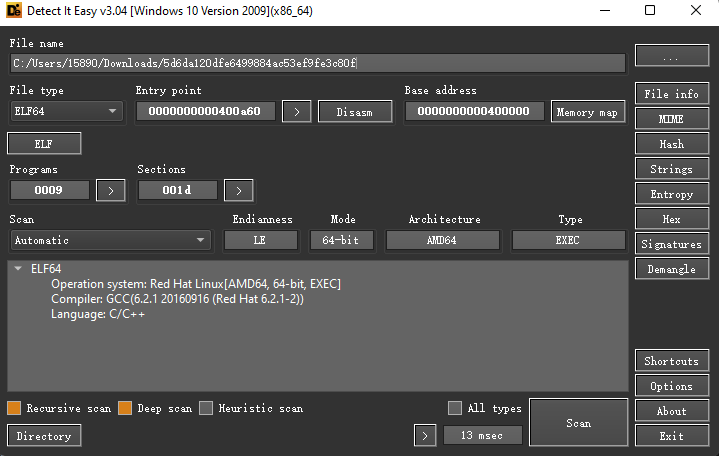
ELF文件,GCC编译,无壳
IDA看下: C++编译的程序文件,看的心烦意乱基本上找不到关键的函数,和关键的位置。
尝试使用下IDA pro的动调寻找一下f关键位置(IDA pro的动态消失配置可以自己网络检索,有很多相关的内容)
先断在第一个跳转位置,即jz short loc_400BD7 位置上
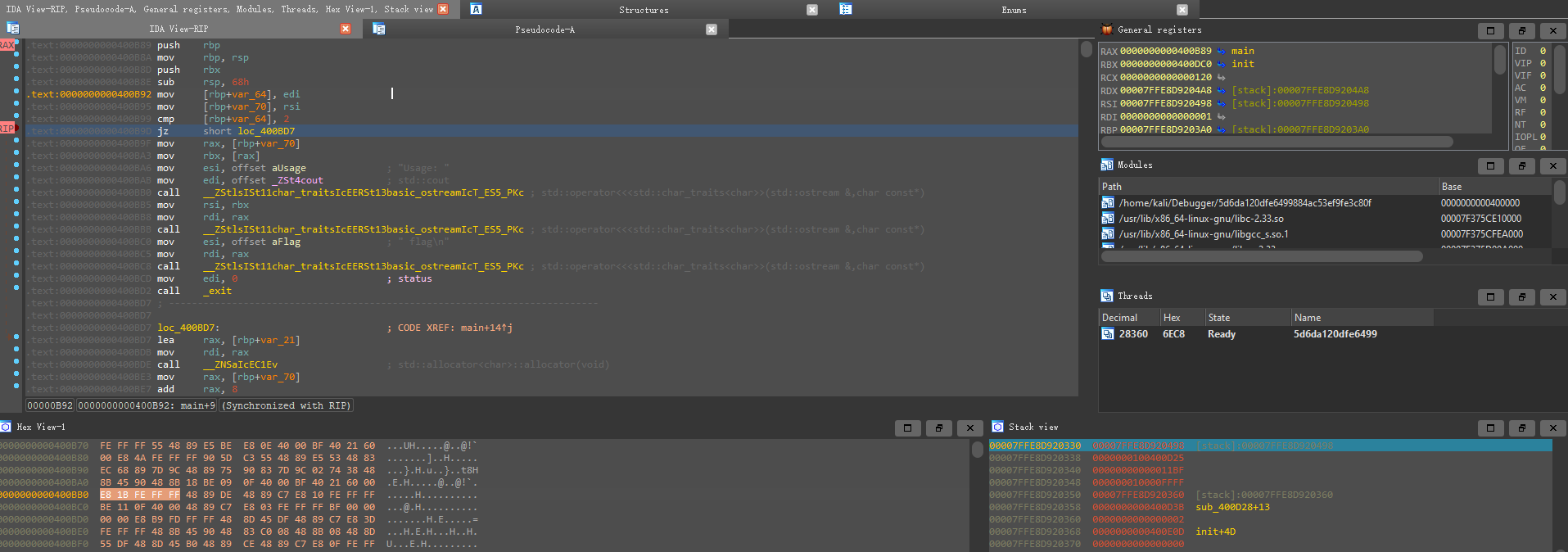
进行几次调试,发现都直接退出,没有进行跳转
也就是 cmp [rbp+var_64], 2 的比较值没有改变ZF标志位
对上面汇编代码进行审计:
main proc near
var_70= qword ptr -70h
var_64= dword ptr -64h
var_60= qword ptr -60h
var_50= byte ptr -50h
var_21= byte ptr -21h
var_20= qword ptr -20h
var_14= dword ptr -14h
push rbp
mov rbp, rsp
push rbx
sub rsp, 68h
mov [rbp+var_64], edi
mov [rbp+var_70], rsi
cmp [rbp+var_64], 2
指令cmp [rbp+var_64], 2是一个条件判断,根据这个语句寻找下变量
rbp+64 = edi
根据Linux x64 fastcall的调用约定,可以知道edi寄存器存储着函数的第一个参数,main函数的第一参数是运行程序附加的参数。所以根据条件,应该是程序运行的时候要携带一个参数进行运行。
因此,尝试使用传参调用来进行寻找关键的函数(当然也可以使用修改ZF标志位)。现在进入下一步的探索:
一路F8寻找退出位置,找到退出位置是在call sub_400B56位置
点开函数看下
sub_400B56 proc near ; CODE XREF: main+F5↓p
push rbp
mov rbp, rsp
mov esi, offset aBetterLuckNext ; "Better luck next time\n"
mov edi, offset _ZSt4cout ; std::cout
call __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc ; std::operator<<<std::char_traits<char>>(std::ostream &,char const*)
mov edi, 0 ; status
call _exit
简单审计下,发现函数,就是一个错误输出的函数,应该不是关键判断的位置。因此,需要往上继续寻找。
退出函数上面有jz short loc_400C83跳转,说明应该是存在条件判断,进行向上寻找条件判断的语句。
找到cmp dl al指令这个应该是核心的条件判断指令
指令比较的是dl寄存器和al寄存器存储的值
dl寄存器是dx寄存器的低位,al寄存器是ax寄存器的低位。相应地,寻找下对eax或rax、edx或rdx的操作
lea rax, [rbp+var_50]
mov rdi, rax
call __ZNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEE3endEv ; std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::end(void)
mov [rbp+var_20], rax
lea rdx, [rbp+var_20]
lea rax, [rbp+var_60]
mov rsi, rdx
mov rdi, rax
call sub_400D3D
test al, al
jz short loc_400C95
lea rax, [rbp+var_60]
mov rdi, rax
call sub_400D9A
movzx edx, byte ptr [rax]
mov rcx, cs:off_6020A0 ; "L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{"...
mov eax, [rbp+var_14]
cdqe
mov eax, dword_6020C0[rax*4]
cdqe
add rax, rcx
movzx eax, byte ptr [rax]
可以寻找到相应的关系,由于C++面向对象STL反汇编实在是比较难搞懂,经过反复调试,发现关键的函数是在这几行:
movzx edx, byte ptr [rax]
mov rcx, cs:off_6020A0 ; "L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{"...
mov eax, [rbp+var_14]
cdqe
mov eax, dword_6020C0[rax*4]
cdqe
add rax, rcx
movzx eax, byte ptr [rax]
对于这个指令,应该就是对数组进行取值组合,可以看下dword_6020C0存储的数据
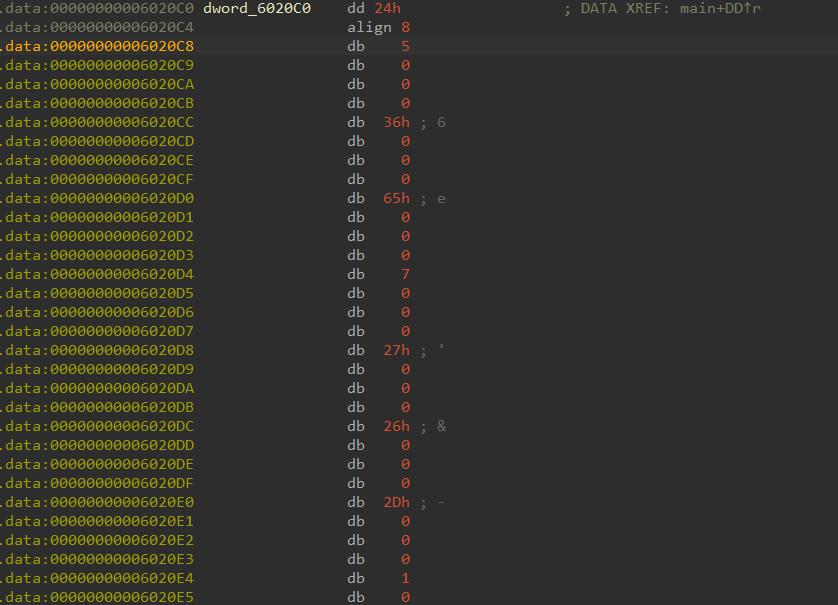 中间的
中间的align 8 指令会根据不同编译器和cpu而呈现不同的行为,align指令简单来说也就是数据宽度对齐,根据数据的规律,可以大致知道是每隔三个0一个有效数据。
上面存储了一个字符串:
.rodata:0000000000400E58 aL3tMeT3llY0uS0 db 'L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t'
.rodata:0000000000400E58 db '_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_1F_Y0u_g0t_1t',0
提取出来的字符串是:
L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_1F_Y0u_g0t_1t
然后提取一下上面数组存储的数据:
unsigned char ida_chars[] =
{
0x24, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x36, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x07, 0x00, 0x00, 0x00, 0x27, 0x00, 0x00, 0x00, 0x26, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0D, 0x00,
0x00, 0x00, 0x56, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x16, 0x00, 0x00, 0x00,
0x02, 0x00, 0x00, 0x00, 0x15, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x29, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00, 0x44, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00,
0x2B, 0x00, 0x00, 0x00
};
现在知道一些已有的数据,下面需要对算法逻辑进行推导: 根据上面找到的关键指令进行C语言代码转化:
int rax = 0;
char str[] = "L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_1F_Y0u_g0t_1t";
unsigned char ida_chars[] =
{
0x24, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x36, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x07, 0x00, 0x00, 0x00, 0x27, 0x00, 0x00, 0x00, 0x26, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0D, 0x00,
0x00, 0x00, 0x56, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x16, 0x00, 0x00, 0x00,
0x02, 0x00, 0x00, 0x00, 0x15, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x29, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00, 0x44, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00,
0x2B, 0x00, 0x00, 0x00
};
if (*(argv + rax) != str[ida_chars[rax*4]]) {
Error_exit();
}
在继续跟逻辑,跟进上面的指令,整体看下汇编,进行C语言整合:
char str[] = "L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_1F_Y0u_g0t_1t";
unsigned char ida_chars[] =
{
0x24, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x36, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00,
0x07, 0x00, 0x00, 0x00, 0x27, 0x00, 0x00, 0x00, 0x26, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0D, 0x00,
0x00, 0x00, 0x56, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x03, 0x00, 0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x2D, 0x00, 0x00, 0x00, 0x16, 0x00, 0x00, 0x00,
0x02, 0x00, 0x00, 0x00, 0x15, 0x00, 0x00, 0x00, 0x03, 0x00,
0x00, 0x00, 0x65, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x29, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00, 0x44, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00,
0x2B, 0x00, 0x00, 0x00
};
for (int i = 0; i < 31; i++) {
if (*(argv + i) != str[ida_chars[i*4]]) {
Error_exit();
}
}
现在主要逻辑基本已经整合成C语言代码,下面根据主要的逻辑,编写一个C语言代码进行求解:
#include <stdio.h>
int main()
{
char string[] = "L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_1F_Y0u_g0t_1";
char ida_chars[] =
{
0x24, 0x00, 0x05, 0x36, 0x65, 0x07, 0x27, 0x26, 0x2D,
0x01, 0x03, 0x00, 0x0D, 0x56, 0x01, 0x03, 0x65, 0x03,
0x2D, 0x16, 0x02, 0x15, 0x03, 0x65, 0x00, 0x29, 0x44,
0x44, 0x01, 0x44, 0x2B
};
char flag[31];
for (int i = 0; i < 31; i++) {
flag[i] = string[ida_chars[i]];
}
printf("%s\n", flag);
return 0;
}
编译并运行程序,得到:
ALEXCTF{W3_L0v3_C_W1th_CL45535}
补充知识:
Linux x64 fastcall 调用约定
- Linux 下的调用约定叫做 “System V AMD64 ABI”,此约定主要在 Solaris,GNU/Linux,FreeBSD 和其他非微软OS上使用;
- Linux 的 x64 下也只有一种函数调用约定,即 __fastcall ,其他调用约定的关键字会被忽略,也就是说 ABI 只有__fastcall ;
- 一个函数在调用时,如果参数个数小于等于 6 个时,前 6 个参数是从左至右依次存放于 RDI,RSI,RDX,RCX,R8,R9 寄存器里面,剩下的参数通过栈传递,从右至左顺序入栈;
- 如果参数个数大于 6 个时,前 5 个参数是从左至右依次存放于 RDI,RSI,RDX,RCX,RAX 寄存器里面,剩下的参数通过栈传递,从右至左顺序入栈;
- 对于系统调用,使用 R10 代替 RCX;
easyRE1
附件中是一个rar文件,解压后的文件夹含有两个文件 一个easy-32文件 一个easy-64文件
查看下文件的大致信息:

ELF x64位程序,通过gcc进行编译的,没有壳 使用IDA pro 查看下程序
push rbp
mov rbp, rsp
sub rsp, 120h
mov [rbp+var_114], edi
mov [rbp+var_120], rsi
mov rax, fs:28h
mov [rbp+var_8], rax
xor eax, eax
mov edi, offset s ; "What is the password?"
call _puts
lea rax, [rbp+s1]
mov rdi, rax
mov eax, 0
call _gets
lea rax, [rbp+s1]
mov esi, offset s2 ; "the password"
mov rdi, rax ; s1
call _strcmp
test eax, eax
jnz short loc_40068F
mov edi, offset aFlagDb2f62a36a ; "FLAG:db2f62a36a018bce28e46d976e3f9864"
call _puts
jmp short loc_400699
loc_40068F: ; CODE XREF: main+5B↑j
mov edi, offset aWrong ; "Wrong!!"
call _puts
发现程序就挺简单的,关键信息就直接呈现出来了
mov edi, offset aFlagDb2f62a36a ; "FLAG:db2f62a36a018bce28e46d976e3f9864"
这道题目的Flag应该就是:
flag{db2f62a36a018bce28e46d976e3f9864}
Reversing-x64Elf-100
查看下文件信息,应该是Elf的文件,使用DIE查看下程序信息
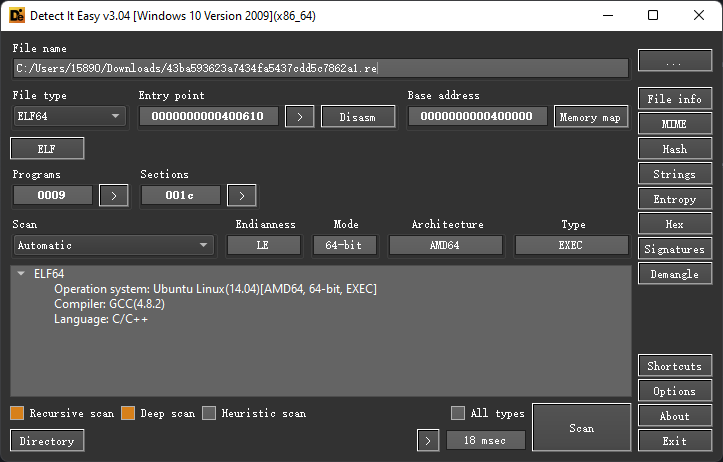
Elf x64程序,没有壳,gcc编译。 使用IDA看下,发现整个程序还是比较简单的,逻辑流程比较清晰
main proc near ; DATA XREF: start+1D↑o
s = byte ptr -110h
var_8 = qword ptr -8
; __unwind {
push rbp
mov rbp, rsp
sub rsp, 110h
mov rax, fs:28h
mov [rbp+var_8], rax
xor eax, eax
mov edi, offset format ; "Enter the password: "
mov eax, 0
call _printf
mov rdx, cs:stdin ; stream
lea rax, [rbp+s]
mov esi, 0FFh ; n
mov rdi, rax ; s
call _fgets
test rax, rax
jz short loc_400866
lea rax, [rbp+s]
mov rdi, rax
call sub_4006FD
test eax, eax
jnz short loc_400855
mov edi, offset s ; "Nice!"
call _puts
mov eax, 0
jmp short loc_40086B
loc_400855: ; CODE XREF: main+5A↑j
mov edi, offset aIncorrectPassw ; "Incorrect password!"
call _puts
mov eax, 1
其实也就是一个判断,来判断flag的数据是否正确,主要应该就是对sub_4006FD函数的分析,
下面就需要进入sub_4006FD函数里面,观察这个函数的行为
sub_4006FD proc near ; CODE XREF: main+53↓p
var_38 = qword ptr -38h
var_24 = dword ptr -24h
var_20 = qword ptr -20h
var_18 = qword ptr -18h
var_10 = qword ptr -10h
push rbp
mov rbp, rsp
mov [rbp+var_38], rdi
mov [rbp+var_24], 0
mov [rbp+var_20], offset aDufhbmf ; "Dufhbmf"
mov [rbp+var_18], offset aPgImos ; "pG`imos"
mov [rbp+var_10], offset aEwuglpt ; "ewUglpt"
mov [rbp+var_24], 0
jmp short loc_40079B
loc_40072D: ; CODE XREF: sub_4006FD+A2↓j
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
add eax, eax
add eax, edx
sub ecx, eax
mov edx, ecx
movsxd rax, edx
mov rsi, [rbp+rax*8+var_20]
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
add eax, eax
cdqe
add rax, rsi
movzx eax, byte ptr [rax]
movsx edx, al
mov eax, [rbp+var_24]
movsxd rcx, eax
mov rax, [rbp+var_38]
add rax, rcx
movzx eax, byte ptr [rax]
movsx eax, al
sub edx, eax
mov eax, edx
cmp eax, 1
jz short loc_400797
mov eax, 1
jmp short loc_4007A6
loc_400797: ; CODE XREF: sub_4006FD+91↑j
add [rbp+var_24], 1
loc_40079B: ; CODE XREF: sub_4006FD+2E↑j
cmp [rbp+var_24], 0Bh
jle short loc_40072D
mov eax, 0
loc_4007A6: ; CODE XREF: sub_4006FD+98↑j
pop rbp
retn
sub_4006FD endp
算法分析
关键应该是根据汇编代码来进行算法解读 找到关键的汇编代码:
jmp short loc_40079B
loc_40072D: ; CODE XREF: sub_4006FD+A2↓j
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
add eax, eax
add eax, edx
sub ecx, eax
mov edx, ecx
movsxd rax, edx
mov rsi, [rbp+rax*8+var_20]
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
add eax, eax
cdqe
add rax, rsi
movzx eax, byte ptr [rax]
movsx edx, al
mov eax, [rbp+var_24]
movsxd rcx, eax
mov rax, [rbp+var_38]
add rax, rcx
movzx eax, byte ptr [rax]
movsx eax, al
sub edx, eax
mov eax, edx
cmp eax, 1
jz short loc_400797
mov eax, 1
jmp short loc_4007A6
loc_400797: ; CODE XREF: sub_4006FD+91↑j
add [rbp+var_24], 1
loc_40079B: ; CODE XREF: sub_4006FD+2E↑j
cmp [rbp+var_24], 0Bh
jle short loc_40072D
mov eax, 0
这一大段代码应该就是关键的汇编代码,开始像剥洋葱一样,一层一层剥下这个程序的逻辑
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
这段代码是 [rpb+var_24] / 3 ,可能看不明白,在《C++反汇编揭秘》一书中给出了除法的汇编运算模型,也算是编译器的一个模型。
$$
\frac{\text{ecx} \cdot M}{2^{n+1}}
$$
这里的M是指mov edx, 55555556h中的数值55555556h,
这里的n是指sar eax, 1Fh中的数值1Fh
根据公式,可以推导出除数的计算公式
$$ 除数 = \frac{2^{n+1}}{M} $$ 根据根据推导的除法公式进行计算,得到除数是3。(关于除法的汇编分析可以阅读看雪一个师傅写的博客:[原创]#30天写作挑战#反汇编代码还原之除数为非2的幂-编程技术-看雪论坛-安全社区|安全招聘|bbs.pediy.com)
现在可以清晰地明白了这段代码就是 :n / 3
接下来,看下面一段代码:
add eax, eax
add eax, edx
sub ecx, eax
mov edx, ecx
这一段代码,是比较容易理解的,结合着上面的代码:
- eax =
n / 3 - edx =
n / 3 - ecx =
n根据信息,这段代码应该就是n - 3 * (n / 3),可能有些人感觉很晕乎,着其实是取余运算,简言之,就是n % 3,仔细分析下,就会发现和n % 3的结果一致。
现在这大段代码就是 n % 3
继续往下走起!
movsxd rax, edx
mov rsi, [rbp+rax*8+var_20]
这个非常简单,就是数组喽,即rbp[n % 3]
接下来往下看
mov ecx, [rbp+var_24]
mov edx, 55555556h
mov eax, ecx
imul edx
mov eax, ecx
sar eax, 1Fh
sub edx, eax
mov eax, edx
add eax, eax
非常明显的除法,这段代码就是2 * (n / 3)
后面紧跟着一段代码:
cdqe
add rax, rsi
movzx eax, byte ptr [rax]
movsx edx, al
其实就是对上面数据的一个整合,也就是
*(rbp[n % 3] + 2 * (n / 3))
现在最难读懂的部分已经过去了,剩下的部分就比较简单,一口气读完
mov eax, [rbp+var_24]
movsxd rcx, eax
mov rax, [rbp+var_38]
add rax, rcx
movzx eax, byte ptr [rax]
movsx eax, al
直接读就行了,结合程序的信息:
- rax :
arg - rcx :
n
所以这段代码就是
*(arg + n)
核心部分已经处理完毕了,再整体审计下代码得到
for (int i = 0; i <= 11; i++) {
if ( *(rbp[ i % 3 ] + 2 * (i / 3)) - *(arg + i) != 1) {
return 1;
}
}
根据这样的代码,可以继续优化下,得到
for (size_t i = 0; i <= 11; i++) {
if ( rbp[i % 3][2 * (i / 3)] - str[i] != 1) {
return 1;
}
}
求解
根据核心代码的分析,可以编写程序进行求解:
#include <stdio.h>
int main()
{
char *v3[4];
v3[0] = "Dufhbmf";
v3[1] = "pG`imos";
v3[2] = "ewUglpt";
char flag[13] = {0};
for(int i = 0; i <= 11; i++)
{
flag[i] = v3[i%3][2*(i/3)] - 1;
}
printf("%s\n", flag);
return 0;
}
编译并运行程序,得到
Code_Talkers
这道题目,主要考察运算的汇编理解。对于汇编的识别还是有一定要求的。至于我为什么不使用IDA pro的F5的Hex-rays插件的功能,我是想要进一步提高自身对于汇编语言的理解,而Hex-rays在很多时候都是无法使用,在真正的逆向工程中,更多的还是人工进行还原,而不是使用IDA的插件进行还原。而且,我是在进行练习,自然是希望挖掘到更多的知识点和技巧点。如果是比赛的话,肯定是更多采用F5的功能。
BABYRE
这道题目,有些技巧,不过总体还是挺有意思的。
看下程序信息先:
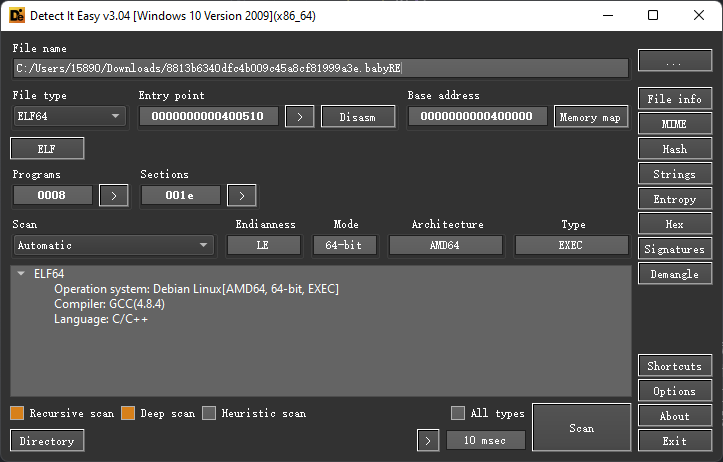
ELF x64程序 GCC编译的程序 使用IDA pro看看
main proc near ; DATA XREF: _start+1D↑o
s = byte ptr -20h
var_8 = dword ptr -8
var_4 = dword ptr -4
; __unwind {
push rbp
mov rbp, rsp
sub rsp, 20h
mov [rbp+var_4], 0
jmp short loc_400637
loc_400617: ; CODE XREF: main+38↓j
mov eax, [rbp+var_4]
cdqe
movzx eax, judge[rax]
xor eax, 0Ch
mov edx, eax
mov eax, [rbp+var_4]
cdqe
mov judge[rax], dl
add [rbp+var_4], 1
loc_400637: ; CODE XREF: main+F↑j
cmp [rbp+var_4], 0B5h
jle short loc_400617
mov edi, offset format ; "Please input flag:"
mov eax, 0
call _printf
lea rax, [rbp+s]
mov rsi, rax
mov edi, offset a20s ; "%20s"
mov eax, 0
call ___isoc99_scanf
lea rax, [rbp+s]
mov rdi, rax ; s
call _strlen
mov [rbp+var_8], eax
cmp [rbp+var_8], 0Eh
jnz short loc_400698
mov edx, offset judge
lea rax, [rbp+s]
mov rdi, rax
call rdx ; judge
test eax, eax
jz short loc_400698
mov edi, offset s ; "Right!"
call _puts
jmp short loc_4006A2
loc_400698: ; CODE XREF: main+72↑j
; main+84↑j
mov edi, offset aWrong ; "Wrong!"
call _puts
loc_4006A2: ; CODE XREF: main+90↑j
mov eax, 0
leave
retn
; } // starts at 400606
main endp
问题分析
主程序的汇编并不很难的样子,但是这里是有坑的
如果直接看主逻辑的话,没有什么难度。 主逻辑就是一个函数判断的问题,如果函数判断成功,就返回正确,错误就返回错误。 但是仔细看下,调用了一个Judge数据,相当于调用了数据。根据这个数据转换成函数会发现这个数据被混淆了。一直集中这个区域,就不知道怎么混淆。怎么跳出这个坑?这个的解决方法就挺简单的,放大一些自己的观测区域,能看到一些关键点
loc_400617: ; CODE XREF: main+38↓j
mov eax, [rbp+var_4]
cdqe
movzx eax, judge[rax]
xor eax, 0Ch
mov edx, eax
mov eax, [rbp+var_4]
cdqe
mov judge[rax], dl
add [rbp+var_4], 1
loc_400637: ; CODE XREF: main+F↑j
cmp [rbp+var_4], 0B5h
jle short loc_400617
这段代码对judge数据进行异或处理,静态观察就不能看到准确的judge数据。如果想要正确看到这个函数的数据,就需要看到运行过程中的运行数据。解决方法有两个,一种是静态解决方案,另一种是动态解决方案。
静态解决方案
采用静态反汇编的方案,也就比较简单,直接在IDA里面嵌入执行脚本,使用执行脚本对数据进行异或修改。IDA pro支持嵌入Python脚本进行异或操作来修改数据。进行异或来得到正确的数据。
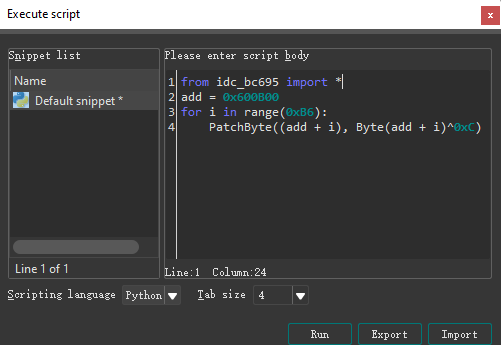
运行一次,然后将judge数据段进行代码转换,就能得到相应的函数:
judge proc near ; CODE XREF: main+80↑p
; DATA XREF: main+16↑r ...
var_28 = qword ptr -28h
var_20 = byte ptr -20h
var_1F = byte ptr -1Fh
var_1E = byte ptr -1Eh
var_1D = byte ptr -1Dh
var_1C = byte ptr -1Ch
var_1B = byte ptr -1Bh
var_1A = byte ptr -1Ah
var_19 = byte ptr -19h
var_18 = byte ptr -18h
var_17 = byte ptr -17h
var_16 = byte ptr -16h
var_15 = byte ptr -15h
var_14 = byte ptr -14h
var_13 = byte ptr -13h
var_4 = dword ptr -4
push rbp
mov rbp, rsp
mov [rbp+var_28], rdi
mov [rbp+var_20], 66h ; 'f'
mov [rbp+var_1F], 6Dh ; 'm'
mov [rbp+var_1E], 63h ; 'c'
mov [rbp+var_1D], 64h ; 'd'
mov [rbp+var_1C], 7Fh
mov [rbp+var_1B], 6Bh ; 'k'
mov [rbp+var_1A], 37h ; '7'
mov [rbp+var_19], 64h ; 'd'
mov [rbp+var_18], 3Bh ; ';'
mov [rbp+var_17], 56h ; 'V'
mov [rbp+var_16], 60h ; '`'
mov [rbp+var_15], 3Bh ; ';'
mov [rbp+var_14], 6Eh ; 'n'
mov [rbp+var_13], 70h ; 'p'
mov [rbp+var_4], 0
jmp short loc_600B71
loc_600B49: ; CODE XREF: judge+75↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
mov edx, [rbp+var_4]
movsxd rcx, edx
mov rdx, [rbp+var_28]
add rdx, rcx
movzx edx, byte ptr [rdx]
mov ecx, [rbp+var_4]
xor edx, ecx
mov [rax], dl
add [rbp+var_4], 1
loc_600B71: ; CODE XREF: judge+47↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B49
mov [rbp+var_4], 0
jmp short loc_600BA9
loc_600B80: ; CODE XREF: judge+AD↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
movzx edx, byte ptr [rax]
mov eax, [rbp+var_4]
cdqe
movzx eax, [rbp+rax+var_20]
cmp dl, al
jz short loc_600BA5
mov eax, 0
jmp short loc_600BB4
loc_600BA5: ; CODE XREF: judge+9C↑j
add [rbp+var_4], 1
loc_600BA9: ; CODE XREF: judge+7E↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B80
mov eax, 1
loc_600BB4: ; CODE XREF: judge+A3↑j
pop rbp
retn
judge endp
动态解决方案
动态解决相对来说会更简单些,就是进行动态调试,使代码运行到指定位置,然后查看数据即可,这样配置可能会有些难度,需要更高的运行性能,但是总体操作相对更简单些。
断点断在mov edi, offset format ; "Please input flag:" 这个指令就好,然后运行下动态调试。断在这个位置,查看下Judge数据就可以得到这个函数:
judge proc near ; CODE XREF: main+80↑p
; DATA XREF: main+16↑r ...
var_28= qword ptr -28h
var_20= byte ptr -20h
var_1F= byte ptr -1Fh
var_1E= byte ptr -1Eh
var_1D= byte ptr -1Dh
var_1C= byte ptr -1Ch
var_1B= byte ptr -1Bh
var_1A= byte ptr -1Ah
var_19= byte ptr -19h
var_18= byte ptr -18h
var_17= byte ptr -17h
var_16= byte ptr -16h
var_15= byte ptr -15h
var_14= byte ptr -14h
var_13= byte ptr -13h
var_4= dword ptr -4
push rbp
mov rbp, rsp
mov [rbp+var_28], rdi
mov [rbp+var_20], 66h ; 'f'
mov [rbp+var_1F], 6Dh ; 'm'
mov [rbp+var_1E], 63h ; 'c'
mov [rbp+var_1D], 64h ; 'd'
mov [rbp+var_1C], 7Fh
mov [rbp+var_1B], 6Bh ; 'k'
mov [rbp+var_1A], 37h ; '7'
mov [rbp+var_19], 64h ; 'd'
mov [rbp+var_18], 3Bh ; ';'
mov [rbp+var_17], 56h ; 'V'
mov [rbp+var_16], 60h ; '`'
mov [rbp+var_15], 3Bh ; ';'
mov [rbp+var_14], 6Eh ; 'n'
mov [rbp+var_13], 70h ; 'p'
mov [rbp+var_4], 0
jmp short loc_600B71
loc_600B49: ; CODE XREF: judge+75↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
mov edx, [rbp+var_4]
movsxd rcx, edx
mov rdx, [rbp+var_28]
add rdx, rcx
movzx edx, byte ptr [rdx]
mov ecx, [rbp+var_4]
xor edx, ecx
mov [rax], dl
add [rbp+var_4], 1
loc_600B71: ; CODE XREF: judge+47↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B49
mov [rbp+var_4], 0
jmp short loc_600BA9
loc_600B80: ; CODE XREF: judge+AD↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
movzx edx, byte ptr [rax]
mov eax, [rbp+var_4]
cdqe
movzx eax, [rbp+rax+var_20]
cmp dl, al
jz short loc_600BA5
mov eax, 0
jmp short loc_600BB4
loc_600BA5: ; CODE XREF: judge+9C↑j
add [rbp+var_4], 1
loc_600BA9: ; CODE XREF: judge+7E↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B80
mov eax, 1
loc_600BB4: ; CODE XREF: judge+A3↑j
pop rbp
retn
judge endp
judge函数分析
现在找到了函数,就需要对函数进行分析来发现关键的判断逻辑,来进行关键步骤的推理分析与判断
对函数大致看一下,应该就是两个for循环了,第一个for循环是对参数进行异或操作,而第二个for循环是对局部变量进行操作。
一段一段地分析吧
mov [rbp+var_4], 0
jmp short loc_600B71
loc_600B49: ; CODE XREF: judge+75↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
mov edx, [rbp+var_4]
movsxd rcx, edx
mov rdx, [rbp+var_28]
add rdx, rcx
movzx edx, byte ptr [rdx]
mov ecx, [rbp+var_4]
xor edx, ecx
mov [rax], dl
add [rbp+var_4], 1
loc_600B71: ; CODE XREF: judge+47↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B49
首先对于这段代码,要知道的一些信息:
[rbp+var_4]: i[rbp+var_28]: rdi –> arg
所以根据这些信息,可以对这段汇编代码进行还原
for (int i = 0; i<= 0xD; i++) {
*(arg+i) = *(arg+i)^i;
}
接着看下面一个循环语句:
mov [rbp+var_4], 0
jmp short loc_600BA9
loc_600B80: ; CODE XREF: judge+AD↓j
mov eax, [rbp+var_4]
movsxd rdx, eax
mov rax, [rbp+var_28]
add rax, rdx
movzx edx, byte ptr [rax]
mov eax, [rbp+var_4]
cdqe
movzx eax, [rbp+rax+var_20]
cmp dl, al
jz short loc_600BA5
mov eax, 0
jmp short loc_600BB4
loc_600BA5: ; CODE XREF: judge+9C↑j
add [rbp+var_4], 1
loc_600BA9: ; CODE XREF: judge+7E↑j
cmp [rbp+var_4], 0Dh
jle short loc_600B80
这段代码应该就是核心判断的逻辑咯,需要知道点信息来进行审计:
[rbp+var_4]: i[rbp+var_28]: rdi –> arg[rbp+var_20]:str[0xD]
根据这些信息进行代码还原,非常简单
for (int i = 0; i <= 0xD; i++) {
if(*(arg+i) != str[i]) {
return 1;
}
}
这个函数的核心逻辑代码已经有了,现在对这个函数的代码进行整合就能得到:
int judge(char *arg) {
char str[0xD+1];
str[0] = 'f';
str[1] = 'm';
str[2] = 'c';
str[3] = 'd';
str[4] = 0x7F;
str[5] = 'k';
str[6] = '7';
str[7] = 'd';
str[8] = ';';
str[9] = 'V';
str[10] = '`';
str[11] = ';';
str[12] = 'n';
str[13] = 'p';
for (int i = 0; i<= 0xD; i++) {
arg[i] = arg[i]^i;
if(arg[i] != str[i]) {
return 1;
}
}
return 0;
}
求解
现在Judge函数算是分析完成了,可以根据函数进行求解了
#include <stdio.h>
#include <string.h>
int main()
{
char data[15] = {0};
char temp[9] = {0};
char flag[14] = {0};
memcpy(data, "fmcd", 4);
data[4] = 127;
memcpy(temp, "k7d;V`;np", 9);
strcat(data,temp);
for (int i = 0; i < 14; i++)
{
flag[i] = data[i] ^ i;
}
printf("%s\n", flag);
return 0;
}
编译代码,并执行得到
flag{n1c3_j0b}k7d;V`;npfmcdk7d;V`;npf
flag就是前半部分,即flag{n1c3_j0b}
这道题目也是可以使用IDA pro的Hex-Rays插件进行F5反编译的,和自己分析的结果基本上是一致的。本菜狗也只是想要提高一下自己的汇编水准,进行了相应的练习。因此并没有使用Hex-Rays插件进行反编译分析,而是直接查看汇编来进行阅读分析。