12 minutes
编码-编写你的快乐
编码
编码是将信息从一种形式转换位另一种形式的过程。它用预先规定的方法将文字、数字或其他对象编成数码,或者将信息、数据转换成规定的电脉冲信号。编码被广泛应用于电子计算机、电视、遥控和通信等方面。解码是编码的逆过程。
编码和解码是个相当广泛的话题,涉及计算机对信息处理的根本方式。编码的目的不是为了让别人看到后解不出来,而是代表信息的另一种表达方式。将原始信息转化为编码信息进行传输,可以解决一些特殊字符、不可见字符的传输问题。接收者将编码信息再转化成原始信息,转化的过程称之为解码。
历史
编码的演变源于人对计算机需求的改变。
- 编码的萌芽——控制码
- ASCII码的出现
- ASCII码的发展——扩展字符集
- 编码的中国化——GBK家族
- 编码的国家化——百家争鸣的编码时代
- 编码的国际化——Unicode编码
- 编码的互联网化——UTF家族
从本质上讲,编码/解码是在做将一种形式的数据翻译为另一种形式的数据的工作。
编码类型
ASCII码
ASCII码是最常见的编码类型。ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符。
ASCII码现在也经常出现在计算编码运输过程中,进行编码,而且在很多编程语言中也经常有用到。
| Bin(二进制) | Oct(八进制) | Dec(十进制) | Hex(十六进制) | 缩写/字符 | 解释 |
|---|---|---|---|---|---|
| 0000 0000 | 00 | 0 | 0x00 | NUL(null) | 空字符 |
| 0000 0001 | 01 | 1 | 0x01 | SOH(start of headline) | 标题开始 |
| 0000 0010 | 02 | 2 | 0x02 | STX (start of text) | 正文开始 |
| 0000 0011 | 03 | 3 | 0x03 | ETX (end of text) | 正文结束 |
| 0000 0100 | 04 | 4 | 0x04 | EOT (end of transmission) | 传输结束 |
| 0000 0101 | 05 | 5 | 0x05 | ENQ (enquiry) | 请求 |
| 0000 0110 | 06 | 6 | 0x06 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 07 | 7 | 0x07 | BEL (bell) | 响铃 |
| 0000 1000 | 010 | 8 | 0x08 | BS (backspace) | 退格 |
| 0000 1001 | 011 | 9 | 0x09 | HT (horizontal tab) | 水平制表符 |
| 0000 1010 | 012 | 10 | 0x0A | LF (NL line feed, new line) | 换行键 |
| 0000 1011 | 013 | 11 | 0x0B | VT (vertical tab) | 垂直制表符 |
| 0000 1100 | 014 | 12 | 0x0C | FF (NP form feed, new page) | 换页键 |
| 0000 1101 | 015 | 13 | 0x0D | CR (carriage return) | 回车键 |
| 0000 1110 | 016 | 14 | 0x0E | SO (shift out) | 不用切换 |
| 0000 1111 | 017 | 15 | 0x0F | SI (shift in) | 启用切换 |
| 0001 0000 | 020 | 16 | 0x10 | DLE (data link escape) | 数据链路转义 |
| 0001 0001 | 021 | 17 | 0x11 | DC1 (device control 1) | 设备控制1 |
| 0001 0010 | 022 | 18 | 0x12 | DC2 (device control 2) | 设备控制2 |
| 0001 0011 | 023 | 19 | 0x13 | DC3 (device control 3) | 设备控制3 |
| 0001 0100 | 024 | 20 | 0x14 | DC4 (device control 4) | 设备控制4 |
| 0001 0101 | 025 | 21 | 0x15 | NAK (negative acknowledge) | 拒绝接收 |
| 0001 0110 | 026 | 22 | 0x16 | SYN (synchronous idle) | 同步空闲 |
| 0001 0111 | 027 | 23 | 0x17 | ETB (end of trans. block) | 结束传输块 |
| 0001 1000 | 030 | 24 | 0x18 | CAN (cancel) | 取消 |
| 0001 1001 | 031 | 25 | 0x19 | EM (end of medium) | 媒介结束 |
| 0001 1010 | 032 | 26 | 0x1A | SUB (substitute) | 代替 |
| 0001 1011 | 033 | 27 | 0x1B | ESC (escape) | 换码(溢出) |
| 0001 1100 | 034 | 28 | 0x1C | FS (file separator) | 文件分隔符 |
| 0001 1101 | 035 | 29 | 0x1D | GS (group separator) | 分组符 |
| 0001 1110 | 036 | 30 | 0x1E | RS (record separator) | 记录分隔符 |
| 0001 1111 | 037 | 31 | 0x1F | US (unit separator) | 单元分隔符 |
| 0010 0000 | 040 | 32 | 0x20 | (space) | 空格 |
| 0010 0001 | 041 | 33 | 0x21 | ! | 叹号 |
| 0010 0010 | 042 | 34 | 0x22 | " | 双引号 |
| 0010 0011 | 043 | 35 | 0x23 | # | 井号 |
| 0010 0100 | 044 | 36 | 0x24 | $ | 美元符 |
| 0010 0101 | 045 | 37 | 0x25 | % | 百分号 |
| 0010 0110 | 046 | 38 | 0x26 | & | 和号 |
| 0010 0111 | 047 | 39 | 0x27 | ' | 闭单引号 |
| 0010 1000 | 050 | 40 | 0x28 | ( | 开括号 |
| 0010 1001 | 051 | 41 | 0x29 | ) | 闭括号 |
| 0010 1010 | 052 | 42 | 0x2A | * | 星号 |
| 0010 1011 | 053 | 43 | 0x2B | + | 加号 |
| 0010 1100 | 054 | 44 | 0x2C | , | 逗号 |
| 0010 1101 | 055 | 45 | 0x2D | - | 减号/破折号 |
| 0010 1110 | 056 | 46 | 0x2E | . | 句号 |
| 0010 1111 | 057 | 47 | 0x2F | / | 斜杠 |
| 0011 0000 | 060 | 48 | 0x30 | 0 | 字符0 |
| 0011 0001 | 061 | 49 | 0x31 | 1 | 字符1 |
| 0011 0010 | 062 | 50 | 0x32 | 2 | 字符2 |
| 0011 0011 | 063 | 51 | 0x33 | 3 | 字符3 |
| 0011 0100 | 064 | 52 | 0x34 | 4 | 字符4 |
| 0011 0101 | 065 | 53 | 0x35 | 5 | 字符5 |
| 0011 0110 | 066 | 54 | 0x36 | 6 | 字符6 |
| 0011 0111 | 067 | 55 | 0x37 | 7 | 字符7 |
| 0011 1000 | 070 | 56 | 0x38 | 8 | 字符8 |
| 0011 1001 | 071 | 57 | 0x39 | 9 | 字符9 |
| 0011 1010 | 072 | 58 | 0x3A | : | 冒号 |
| 0011 1011 | 073 | 59 | 0x3B | ; | 分号 |
| 0011 1100 | 074 | 60 | 0x3C | < | 小于 |
| 0011 1101 | 075 | 61 | 0x3D | = | 等号 |
| 0011 1110 | 076 | 62 | 0x3E | > | 大于 |
| 0011 1111 | 077 | 63 | 0x3F | ? | 问号 |
| 0100 0000 | 0100 | 64 | 0x40 | @ | 电子邮件符号 |
| 0100 0001 | 0101 | 65 | 0x41 | A | 大写字母A |
| 0100 0010 | 0102 | 66 | 0x42 | B | 大写字母B |
| 0100 0011 | 0103 | 67 | 0x43 | C | 大写字母C |
| 0100 0100 | 0104 | 68 | 0x44 | D | 大写字母D |
| 0100 0101 | 0105 | 69 | 0x45 | E | 大写字母E |
| 0100 0110 | 0106 | 70 | 0x46 | F | 大写字母F |
| 0100 0111 | 0107 | 71 | 0x47 | G | 大写字母G |
| 0100 1000 | 0110 | 72 | 0x48 | H | 大写字母H |
| 0100 1001 | 0111 | 73 | 0x49 | I | 大写字母I |
| 01001010 | 0112 | 74 | 0x4A | J | 大写字母J |
| 0100 1011 | 0113 | 75 | 0x4B | K | 大写字母K |
| 0100 1100 | 0114 | 76 | 0x4C | L | 大写字母L |
| 0100 1101 | 0115 | 77 | 0x4D | M | 大写字母M |
| 0100 1110 | 0116 | 78 | 0x4E | N | 大写字母N |
| 0100 1111 | 0117 | 79 | 0x4F | O | 大写字母O |
| 0101 0000 | 0120 | 80 | 0x50 | P | 大写字母P |
| 0101 0001 | 0121 | 81 | 0x51 | Q | 大写字母Q |
| 0101 0010 | 0122 | 82 | 0x52 | R | 大写字母R |
| 0101 0011 | 0123 | 83 | 0x53 | S | 大写字母S |
| 0101 0100 | 0124 | 84 | 0x54 | T | 大写字母T |
| 0101 0101 | 0125 | 85 | 0x55 | U | 大写字母U |
| 0101 0110 | 0126 | 86 | 0x56 | V | 大写字母V |
| 0101 0111 | 0127 | 87 | 0x57 | W | 大写字母W |
| 0101 1000 | 0130 | 88 | 0x58 | X | 大写字母X |
| 0101 1001 | 0131 | 89 | 0x59 | Y | 大写字母Y |
| 0101 1010 | 0132 | 90 | 0x5A | Z | 大写字母Z |
| 0101 1011 | 0133 | 91 | 0x5B | [ | 开方括号 |
| 0101 1100 | 0134 | 92 | 0x5C | \ | 反斜杠 |
| 0101 1101 | 0135 | 93 | 0x5D | ] | 闭方括号 |
| 0101 1110 | 0136 | 94 | 0x5E | ^ | 脱字符 |
| 0101 1111 | 0137 | 95 | 0x5F | _ | 下划线 |
| 0110 0000 | 0140 | 96 | 0x60 | ` | 开单引号 |
| 0110 0001 | 0141 | 97 | 0x61 | a | 小写字母a |
| 0110 0010 | 0142 | 98 | 0x62 | b | 小写字母b |
| 0110 0011 | 0143 | 99 | 0x63 | c | 小写字母c |
| 0110 0100 | 0144 | 100 | 0x64 | d | 小写字母d |
| 0110 0101 | 0145 | 101 | 0x65 | e | 小写字母e |
| 0110 0110 | 0146 | 102 | 0x66 | f | 小写字母f |
| 0110 0111 | 0147 | 103 | 0x67 | g | 小写字母g |
| 0110 1000 | 0150 | 104 | 0x68 | h | 小写字母h |
| 0110 1001 | 0151 | 105 | 0x69 | i | 小写字母i |
| 0110 1010 | 0152 | 106 | 0x6A | j | 小写字母j |
| 0110 1011 | 0153 | 107 | 0x6B | k | 小写字母k |
| 0110 1100 | 0154 | 108 | 0x6C | l | 小写字母l |
| 0110 1101 | 0155 | 109 | 0x6D | m | 小写字母m |
| 0110 1110 | 0156 | 110 | 0x6E | n | 小写字母n |
| 0110 1111 | 0157 | 111 | 0x6F | o | 小写字母o |
| 0111 0000 | 0160 | 112 | 0x70 | p | 小写字母p |
| 0111 0001 | 0161 | 113 | 0x71 | q | 小写字母q |
| 0111 0010 | 0162 | 114 | 0x72 | r | 小写字母r |
| 0111 0011 | 0163 | 115 | 0x73 | s | 小写字母s |
| 0111 0100 | 0164 | 116 | 0x74 | t | 小写字母t |
| 0111 0101 | 0165 | 117 | 0x75 | u | 小写字母u |
| 0111 0110 | 0166 | 118 | 0x76 | v | 小写字母v |
| 0111 0111 | 0167 | 119 | 0x77 | w | 小写字母w |
| 0111 1000 | 0170 | 120 | 0x78 | x | 小写字母x |
| 0111 1001 | 0171 | 121 | 0x79 | y | 小写字母y |
| 0111 1010 | 0172 | 122 | 0x7A | z | 小写字母z |
| 0111 1011 | 0173 | 123 | 0x7B | { | 开花括号 |
| 0111 1100 | 0174 | 124 | 0x7C | | | 垂线 |
| 0111 1101 | 0175 | 125 | 0x7D | } | 闭花括号 |
| 0111 1110 | 0176 | 126 | 0x7E | ~ | 波浪号 |
| 0111 1111 | 0177 | 127 | 0x7F | DEL (delete) | 删除 |
hex编码
hex是最常用的编码方式之一,这一点非常容易理解,就是将信息转化为十六进制。要进行各类编码的转化,或者是要将信息在计算机存储中最为本质的一面表现出来的时候,都可以使用hex编码方式。Hex编码就是把一个8位的字节数据用两个十六进制数展示出来,编码时,将8位二进制码重新分组成两个4位的字节,其中一个字节的低4位是原字节的高四位,另一个字节的低4位是原数据的低4位,高4位都补0,然后输出这两个字节对应十六进制数字作为编码。Hex编码后的长度是源数据的2倍。
Base家族
Base家族,最著名的就是Base64编码,在计算机的数据传输过程中也经常用到,Base64编码在RSA签名算法也都有用到,是一种比较基础的编码方式。Base家族的编码实质上就是进制的转换。
Base编码是怎么来的呢?
1970~1980 年代,DEC(和其他公司)生产的“微型计算机”使用的字符编码为 ASCII。 每个字节使用 7 位,给出 128 个可用值。 这足以满足大写和小写拉丁字母,数字,标点,一些常见的数学符号,货币符号和控制字符的需要。此后 ASCII 变得非常流行,并在很长一段时间内占主导地位。ASCII 规定了范围在 [0,127] 之间的字符编码,其中 [0, 31] 以及 127 (del) 这 33 个属于不可打印的控制字符(可以使用 man ascii 查证)。互联网的杀手级应用——电子邮件系统当初是为了传输 7 位 ASCII 文本而设计的,于是在传输信息时,有些邮件网关会把 [0,31] 这些控制字符给清除,而有些会替换 10 (newline 或 \n)和 13 (carrige 或 \r) 字符,有些更加粗暴地将二进制的最高位清空,还有的程序在收到 [128, 255 ] 之间的国际字符会发生错误。
如何在不同邮件网关之间安全地传输控制字符、国际字符和二进制文件呢?作为 MIME(RFC 2045 和 RFC 3548)多媒体电子邮件标准的一部分的 Base64 编码就被开发出来了。
Base64 用于编码邮件内容、网页图片,意在减少传输过程中可能出现的错误;Base58 是比特币地址使用的编码方法,旨在提高地址的辨识度;Base32 用在一些对大小写不敏感的文件系统中。每种 Base-x 的编码都有适合它们的应用场景。
Base编码从底层来说就是对数据进行进制转换,Base64是64进制,Base32是32进制,Base16是16进制。而中间的过程是为了更好地进行传输数据。
URL编码
url编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。
URL编码是比较常见的编码类型,在浏览器进行数据传输的过程中会经常使用到,可以用于构造反序列化对象、SQL注入绕过、文件包含绕过等等。
URL编码参考手册:
| ASCII 字符 | URL-编码 |
|---|---|
| space | %20 |
| ! | %21 |
| " | %22 |
| # | %23 |
| $ | %24 |
| % | %25 |
| & | %26 |
| ' | %27 |
| ( | %28 |
| ) | %29 |
| * | %2A |
| + | %2B |
| , | %2C |
| - | %2D |
| . | %2E |
| / | %2F |
| 0 | %30 |
| 1 | %31 |
| 2 | %32 |
| 3 | %33 |
| 4 | %34 |
| 5 | %35 |
| 6 | %36 |
| 7 | %37 |
| 8 | %38 |
| 9 | %39 |
| : | %3A |
| ; | %3B |
| < | %3C |
| = | %3D |
| > | %3E |
| ? | %3F |
| @ | %40 |
| A | %41 |
| B | %42 |
| C | %43 |
| D | %44 |
| E | %45 |
| F | %46 |
| G | %47 |
| H | %48 |
| I | %49 |
| J | %4A |
| K | %4B |
| L | %4C |
| M | %4D |
| N | %4E |
| O | %4F |
| P | %50 |
| Q | %51 |
| R | %52 |
| S | %53 |
| T | %54 |
| U | %55 |
| V | %56 |
| W | %57 |
| X | %58 |
| Y | %59 |
| Z | %5A |
| [ | %5B |
| \ | %5C |
| ] | %5D |
| ^ | %5E |
| _ | %5F |
| ` | %60 |
| a | %61 |
| b | %62 |
| c | %63 |
| d | %64 |
| e | %65 |
| f | %66 |
| g | %67 |
| h | %68 |
| i | %69 |
| j | %6A |
| k | %6B |
| l | %6C |
| m | %6D |
| n | %6E |
| o | %6F |
| p | %70 |
| q | %71 |
| r | %72 |
| s | %73 |
| t | %74 |
| u | %75 |
| v | %76 |
| w | %77 |
| x | %78 |
| y | %79 |
| z | %7A |
| { | %7B |
| | | %7C |
| } | %7D |
| ~ | %7E |
| %7F | |
| ` | %80 |
| | %81 |
| ‚ | %82 |
| ƒ | %83 |
| „ | %84 |
| … | %85 |
| † | %86 |
| ‡ | %87 |
| ˆ | %88 |
| ‰ | %89 |
| Š | %8A |
| ‹ | %8B |
| Π| %8C |
| | %8D |
| Ž | %8E |
| | %8F |
| | %90 |
| ' | %91 |
| ' | %92 |
| " | %93 |
| " | %94 |
| • | %95 |
| – | %96 |
| — | %97 |
| ˜ | %98 |
| ™ | %99 |
| š | %9A |
| › | %9B |
| œ | %9C |
| | %9D |
| ž | %9E |
| Ÿ | %9F |
| %A0 | |
| ¡ | %A1 |
| ¢ | %A2 |
| £ | %A3 |
| ¤ | %A4 |
| ¥ | %A5 |
| ¦ | %A6 |
| § | %A7 |
| ¨ | %A8 |
| © | %A9 |
| ª | %AA |
| « | %AB |
| ¬ | %AC |
| | %AD |
| ® | %AE |
| ¯ | %AF |
| ° | %B0 |
| ± | %B1 |
| ² | %B2 |
| ³ | %B3 |
| ´ | %B4 |
| µ | %B5 |
| ¶ | %B6 |
| · | %B7 |
| ¸ | %B8 |
| ¹ | %B9 |
| º | %BA |
| » | %BB |
| ¼ | %BC |
| ½ | %BD |
| ¾ | %BE |
| ¿ | %BF |
| À | %C0 |
| Á | %C1 |
| Â | %C2 |
| Ã | %C3 |
| Ä | %C4 |
| Å | %C5 |
| Æ | %C6 |
| Ç | %C7 |
| È | %C8 |
| É | %C9 |
| Ê | %CA |
| Ë | %CB |
| Ì | %CC |
| Í | %CD |
| Î | %CE |
| Ï | %CF |
| Ð | %D0 |
| Ñ | %D1 |
| Ò | %D2 |
| Ó | %D3 |
| Ô | %D4 |
| Õ | %D5 |
| Ö | %D6 |
| × | %D7 |
| Ø | %D8 |
| Ù | %D9 |
| Ú | %DA |
| Û | %DB |
| Ü | %DC |
| Ý | %DD |
| Þ | %DE |
| ß | %DF |
| à | %E0 |
| á | %E1 |
| â | %E2 |
| ã | %E3 |
| ä | %E4 |
| å | %E5 |
| æ | %E6 |
| ç | %E7 |
| è | %E8 |
| é | %E9 |
| ê | %EA |
| ë | %EB |
| ì | %EC |
| í | %ED |
| î | %EE |
| ï | %EF |
| ð | %F0 |
| ñ | %F1 |
| ò | %F2 |
| ó | %F3 |
| ô | %F4 |
| õ | %F5 |
| ö | %F6 |
| ÷ | %F7 |
| ø | %F8 |
| ù | %F9 |
| ú | %FA |
| û | %FB |
| ü | %FC |
| ý | %FD |
| þ | %FE |
| ÿ | %FF |
HTML编码
HTML编码在HTML文件中经常会使用到,在信息传输过程中并不是非常常见。HTML编码也叫HTML字符实体。是HTML编写过程中使用特殊的编码符号来进行网页页面符号的正确显示,是网页上面的一种编码格式。
HTML 实体是一段以连字号(&)开头、以分号(;)结尾的文本(字符串)。实体常常用于显示保留字符(这些字符会被解析为 HTML 代码)和不可见的字符(如“不换行空格”)。你也可以用实体来代替其他难以用标准键盘键入的字符。
很多字符都有易于记忆的实体。例如版权符号 (
©) 的实体是©。对于没那么容易记住的字符,例如—或—,你可以查看 参考表 或使用 解码工具 。
| 显示结果 | 描述 | 实体名称 | 实体编号 |
|---|---|---|---|
| 空格 | | ||
| < | 小于号 | < | < |
| > | 大于号 | > | > |
| & | 和号 | & | & |
| " | 引号 | " | " |
| ' | 撇号 | ' (IE不支持) | ' |
| ¢ | 分(cent) | ¢ | ¢ |
| £ | 镑(pound) | £ | £ |
| ¥ | 元(yen) | ¥ | ¥ |
| € | 欧元(euro) | € | € |
| § | 小节 | § | § |
| © | 版权(copyright) | © | © |
| ® | 注册商标 | ® | ® |
| ™ | 商标 | ™ | ™ |
| × | 乘号 | × | × |
| ÷ | 除号 | ÷ | ÷ |
Unicode编码
Unicode 是一种字符集标准,用于对来自世界上不同语言、文字系统和符号进行编号和字符定义。通过给每个字符分配一个编号,程序员可以创建字符编码,让计算机在同一个文件或程序中存储、处理和传输任何语言组合。
在 Unicode 定义之前,在同一数据中混合使用不同的语言是很困难的,而且容易出错。例如,一个字符集存储的是日文字符,而另一个字符集存储的是阿拉伯字母。如果没有明确标明数据的哪些部分属于哪个字符集,其他程序和计算机就会错误地显示文本,或者在处理过程中损坏文本。如果你曾经见过像 (“”) 被替换为胡言乱语 £,那么你就已经看到过这个被称为 Mojibake 的问题。
网络上最常见的 Unicode 字符编码是UTF-8。还存在一些其他编码,如 UTF-16或过时的 UCS-2,但推荐使用 UTF-8。
Unicode编码也被称为万国码,是比较常见的编码格式,在计算机中经常会使用到Unicode编码进行互联网上应用的传输和编写。
Morse电码
Morse电码也叫Morsecode,是大家耳熟能详的编码方式,很多人都误认为它是一种加密方式,但其实它是一种编码,因为它并不存在密钥。
Morsecode的编码形式非常容易识别,就是.--- .-.--等类似的形式,非常容易识别并进行解码。

JSFuck
jsfuck是一种非常有意思的编码方式,仅使用6个字符就可以书写任意的JavaScript代码。从直观上非常容易辨别出这种编码方式,只需要“()+[]!”这6个字符组成的字符串。jsfuck的编码和解码与morsecode类似,只不过其表示的是JavaScript的语句。jsfuck源于一门编程语言brainfuck,其主要的思想就是只使用8种特定的符号来编写代码。jsfuck也是沿用了这个思想,它仅仅使用6种符号来编写代码。它们分别是()+[]!
JSFuck可以使用jsfuck官方的网站进行解密:[JSFuck - Write any JavaScript with 6 Characters: !+](http://www.jsfuck.com/)
比如:
alert(1)
就可以被jsfuck编码为:
[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(+(!+[]+!+[]+!+[]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[!+[]+!+[]])+(![]+[])[+!+[]]+(![]+[])[!+[]+!+[]])()((![]+[])[+!+[]]+(![]+[])[!+[]+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[!+[]+!+[]+!+[]]]+[+!+[]]+([+[]]+![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[!+[]+!+[]+[+[]]])
Quoted-Printable编码
Quoted-printable 可译为“可打印字符引用编码”、“使用可打印字符的编码”,我们收邮件,查看信件原始信息,经常会看到这种类型的编码!
Quoted-printable或QP encoding,没有规范的中文译名,可译为可打印字符引用编码或使用可打印字符的编码。Quoted-printable是使用可打印的ASCII字符(如字母、数字与“=”)表示各种编码格式下的字符,以便能在7-bit数据通路上传输8-bit数据, 或者更一般地说在非8-bit clean媒体上正确处理数据。这被定义为MIME content transfer encoding,用于e-mail。QP使用“=”开头的转义字符. 一般限制行宽为76,因为有些软件限制了行宽.
MIME定义了在e-mail中发送各种信息的方法, 包括非英语的其它语言文本信息, 使用非ASCII的其它字符编码。这些编码常常使用ASCII范围以外的值来编码字符,因此需要进一步被编码以便适用于non-8-bit-clean环境。Quoted-printable编码就是把任意字节序列映射为ASCII字符序列。Quoted-printable自身并不是一种字符编码方案, 而是一种在面向字节的编码时的数据编码布置(data coding layer),即由编码的字符序列如何表示为字节流QP是可逆的,即可以由原来的非ASCII字符流与QP编码后的字节流来回转换而不失信息。
Quoted-printable与Base64是两种基本的MIME内容传输编码, 如果通常的“8bit”编码不适用。如果文本不含很多非ASCII字符,quoted-printable编码的结果的可读性相当好[注 2]而且紧凑。但是,如果输入的大多数是非ASCII字符,那么quoted-printable编码将变得既不可读又非常低效。Base64并不是人可读的,但对于所有数据其成本均匀,适用于二进制数据与非拉丁字母语言文本。
比如:
密码学
可以使用Quoted-printable编码为:
=E5=AF=86=E7=A0=81=E5=AD=A6=0A=09=09=09=09=09
Quoted-printable的编码形式也比较容易辨认,基本上就是字符加等于号构成编码文段格式。
BrainFuck编码
BrainFuck是一种编程语言,也可以作为一种编码的手段进行编码,对文本进行BrainFuck编码然后进行快速传输。
Brainfuck,是一种极小化的程序语言,它是由Urban Müller在1993年创造的。由于fuck在英语中是脏话,这种语言有时被称为Brainf*ck或Brainf***,或被简称为BF。
Müller的目标是创建一种简单的、可以用最小的编译器来实现的、符合图灵完全思想的编程语言。这种语言由八种运算符构成,为Amiga机器编写的编译器(第二版)只有240个字节大小。就像它的名字所暗示的,Brainfuck程序很难读懂。尽管如此,Brainfuck图灵机一样可以完成任何计算任务。虽然Brainfuck的计算方式如此与众不同,但它确实能够正确运行。这种语言基于一个简单的机器模型,除了指令,这个机器还包括:一个以字节为单位、被初始化为零的数组、一个指向该数组的指针(初始时指向数组的第一个字节)、以及用于输入输出的两个字节流。
比如:
Hello world!
使用BrainFuck进行编码就会得到
+++++ +++[- >++++ ++++< ]>+++ +++++ .<+++ ++[-> +++++ <]>++ ++.++ +++++
..+++ .<+++ +++++ [->-- ----- -<]>- ----- ----- ----. <++++ +++[- >++++
+++<] >++++ ++.<+ +++[- >++++ <]>++ +++++ +.+++ .---- --.-- ----- -.<++
+++++ +[->- ----- --<]> ---.<
可以使用Brainfuck/Ook! Obfuscation/Encoding 这个网站进行编码和解码
Ook编码
Ook也是一种小型的编程语言,Ook是为红毛猩猩设计的编程语言,设计思路和BrainFuck的设计思路基本类似,但是Ook采用了更少的元素进行编程,语句更加简单。由于Ook的特点,因此Ook也可以设计为一种特殊的编码方式。
比如:
Hello world!
使用Ook编码后,得到
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook!
Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook!
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook! Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook.
Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook?
Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook.
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook?
Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook.
非常长,进行Ook编码和解码的网站也是Brainfuck/Ook! Obfuscation/Encoding
UUencode编码
一种逐渐退出历史舞台的编码方式,编码的文段中有许多特殊的字符。
uuencode这个名字是衍生自"Unix-to-Unix encoding",原先是Unix系统下将二进制的资料借由uucp邮件系统传输的一个编码程式,是一种二进制到文字的编码。uudecode是与uuencode搭配的解码程式,uuencode/decode常见于电子邮件中的档案传送以及usenet新闻组和BBS的贴文等等。近来已被MIME所大量取代。
UUencode的编码原理和Base64的编码原理非常相似。
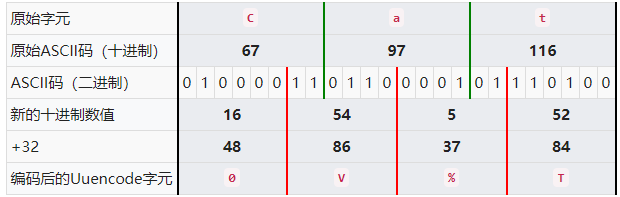
比如:
Hello World!
进行编码后得到:
,2&5L;&\@5V]R;&0A
XXencode编码
XXencode编码和base64编码类似,只不过是使用的转换表不同。
Xxencode编码,也是一个二进制字符转换为普通打印字符方法。跟UUencode编码原理方法很相似,唯独不同的是可打印字符不同。通个UUencode编码,我们知道它有个缺点就是,64个可打印字符中,有很多的特殊字符。而XXencode编码方法,对64个原字符有做规范。这里它有跟Base64类型了。都有指定可打印字符范围、及编号。Xxencode编码在上世纪后期,IBM大型机中得到很广泛的应用。现在逐渐被Base64编码转换方法所取代了。
比如:
Hello World!
进行XXencode编码后,得到
BG4JgP4wUJqxmP4EV0U++
JJencode编码
算是JSFuck编码的前身,是由18种字符组成的编码格式。是针对JavaScript进行设计的编码方式。
长谷川阳介(Yosuke Hasegawa)于2009年7月创建了一个名为“jjencode”的网络应用程序,可将一切的JavaScript代码混淆为!+,"$.:;_{}~=这十八个字符的排列组合。
比如:
alert("Hello, JavaScript" )
进行jjencode编码,得到
$=~[];$={___:++$,$$$$:(![]+"")[$],__$:++$,$_$_:(![]+"")[$],_$_:++$,$_$$:({}+"")[$],$$_$:($[$]+"")[$],_$$:++$,$$$_:(!""+"")[$],$__:++$,$_$:++$,$$__:({}+"")[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+"")[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+"")[$.__$])+((!$)+"")[$._$$]+($.__=$.$_[$.$$_])+($.$=(!""+"")[$.__$])+($._=(!""+"")[$._$_])+$.$_[$.$_$]+$.__+$._$+$.$;$.$$=$.$+(!""+"")[$._$$]+$.__+$._+$.$+$.$$;$.$=($.___)[$.$_][$.$_];$.$($.$($.$$+"\""+$.$_$_+(![]+"")[$._$_]+$.$$$_+"\\"+$.__$+$.$$_+$._$_+$.__+"(\\\"\\"+$.__$+$.__$+$.___+$.$$$_+(![]+"")[$._$_]+(![]+"")[$._$_]+$._$+",\\"+$.$__+$.___+"\\"+$.__$+$.__$+$._$_+$.$_$_+"\\"+$.__$+$.$$_+$.$$_+$.$_$_+"\\"+$.__$+$._$_+$._$$+$.$$__+"\\"+$.__$+$.$$_+$._$_+"\\"+$.__$+$.$_$+$.__$+"\\"+$.__$+$.$$_+$.___+$.__+"\\\"\\"+$.$__+$.___+")"+"\"")())();
AAencode编码
aaencode编码是一个比较有意思的编码形式,同样也是对于JavaScript语言设计的编码方式,是把JavaScript的代码编码成日本的表情包。
比如:
alert("Hello, JavaScript")
通过aaencode编码,得到
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] = ((゚Д゚)+'_') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) ['o'] = ((゚Д゚)+'_') [゚Θ゚];(゚o゚)=(゚Д゚) ['c']+(゚Д゚) ['o']+(゚ω゚ノ +'_')[゚Θ゚]+ ((゚ω゚ノ==3) +'_') [゚ー゚] + ((゚Д゚) +'_') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +'_') [゚Θ゚]+((゚ー゚==3) +'_') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) ['c']+((゚Д゚)+'_') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) ['o']+((゚ー゚==3) +'_') [゚Θ゚];(゚Д゚) ['_'] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +'_') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+'_') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +'_') [o^_^o -゚Θ゚]+((゚ー゚==3) +'_') [゚Θ゚]+ (゚ω゚ノ +'_') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]='\\'; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +'_')[c^_^o];(゚Д゚) [゚o゚]='\"';(゚Д゚) ['_'] ( (゚Д゚) ['_'] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚o゚]) (゚Θ゚)) ('_');